Research Log: vLLM & SWE Agent — Feb 1, 2026
February 1, 2026
Context
I had previously trained the Qwen/Qwen2.5-Coder-3B model on H200 and set up vLLM for parallel inference on RunPod for the inference phase of the SWE Benchmark.
The evaluation phase was run on a 32 vCPU Hetzner server, using the prediction files produced in the inference phase.
I found that most evaluation runs were exiting early for various reasons.
After talking with my advisor, I realized we needed to use the standard SWE Agent for evaluation, not the current setup.
What I did today
- Simulated the RunPod model-serving flow on a low-end GPU; since vLLM dependencies were already working, it succeeded on the first try
- Ran into many issues on the SWE Agent evaluation side (the vCPU server), but eventually got the full pipeline running
- The first evaluation results were very discouraging; after some adjustments, I fixed the RunPod HTTP port connectivity issue and could continue with the rest of the pipeline
- Updated the model. After a lot of errors, I found that the base model itself was problematic, so I switched to
Qwen/Qwen2.5-Coder-3B-Instruct
and for now I’m only testing the pre-SFT model pass rate on SWE Lite- My expectations for the experiment:
- The base model has some pass rate
- A small gain after SFT
- Further gain after refining on the dataset
- My expectations for the experiment:
- One aside: I found that SWE Agent evaluation is multi-turn interaction with the model,
while the data we use for training—SWE-Gym / OpenHands-SFT-Trajectories—consists of very long tool-call trajectories, often 30k+ tokens
That made me wonder:Is training on OpenHands data actually effective for improving on the SWE Agent benchmark?
After going back and forth with AI, I concluded that the approach is plausible in principle - After running, submitted rate was very low, with various abnormal exits
- Running ~300 evaluations takes about 1 hour
- While putting the kid to sleep, the terminal was accidentally closed, so I didn’t see the final results
- I then changed the SWE Agent YAML config and tuned the number of workers on the Hetzner server to 6
- I still ended up using the old YAML
- There’s clearly more room to optimize, but the pipeline can now run continuously
- Submitted rate improved somewhat
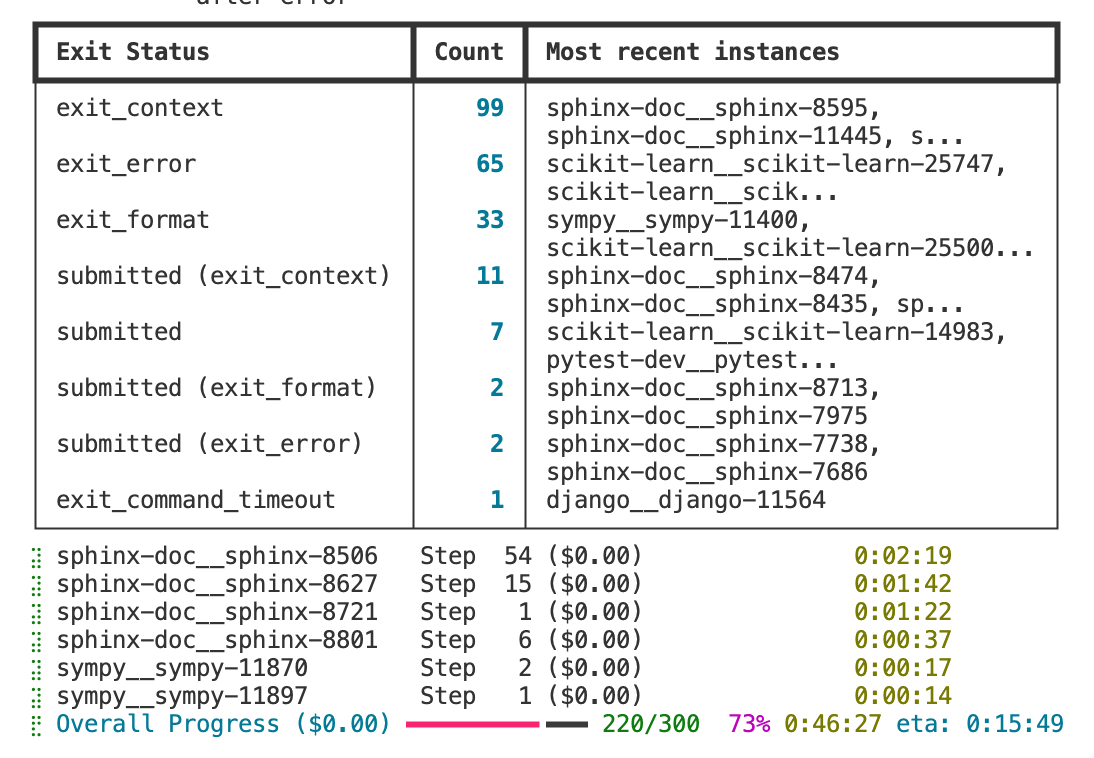 SWE Lite evaluation in progress
SWE Lite evaluation in progress