Daily Log: Evaluation Complete & Results Overview — Feb 22, 2026
Overview
After a series of sustained runs, the Perplexity evaluation phase is now fully complete. Results have been generated for all experimental groups. Systematic result analysis has not yet been conducted, but the experimental work is largely wrapped up.
Evaluation Results
The chart below shows the Mean Cross-Entropy Loss for each model across three test sets: Gold (high-quality), Random, and Low-Q (low-quality):
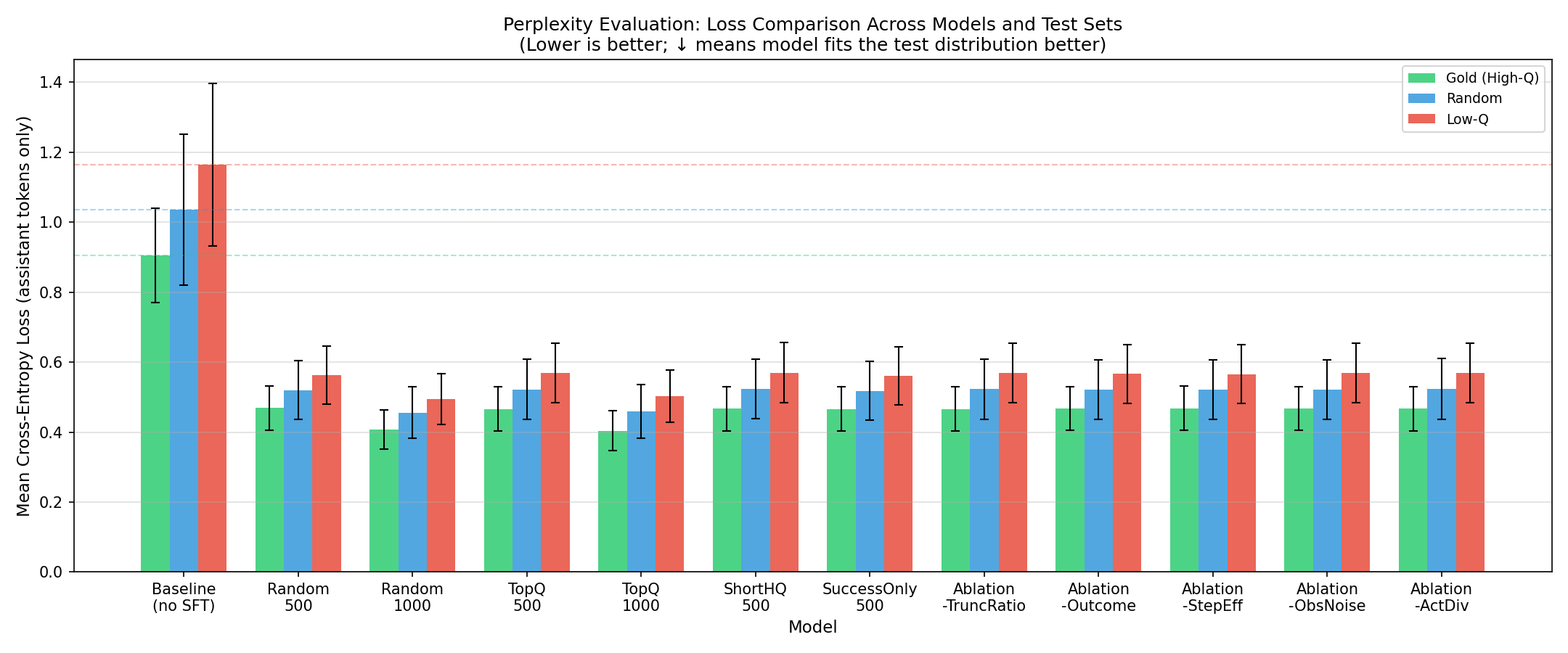
Key observations from the results:
- Baseline (no SFT) shows the highest loss — roughly 1.18 on the Low-Q test set — confirming that the untuned model fits the target distribution worst
- All SFT-trained models show a dramatic reduction in loss, converging in the 0.45–0.60 range, indicating that fine-tuning effectively improves distribution alignment
- Gold test set losses are consistently lower than Random and Low-Q across models, which aligns with the expectation that models trained on high-quality data fit better against high-quality test distributions
- Ablation variants (TruncRatio, Outcome, StepEff, ObsNoise, ActDiv) show relatively small differences from each other — a closer analysis is needed to quantify their individual contributions
Next Steps
With the experimental phase largely complete, the focus now shifts to writing and publication:
- Assess paper feasibility: Review the evaluation results and determine whether the contributions are substantive enough to meet the innovation bar of the target venue
- Finalize submission plan: Weigh paper quality, timeline, and practical constraints to identify the most appropriate submission target
Summary
The experimental work is substantially done. If further results or comparisons are needed later, refinements can be made accordingly. The immediate priority is synthesizing results and completing the paper, moving toward the final stage of the research.