Research Log: Optimizing SWE-agent Evaluation Pipelines — Feb 2, 2026
📝 Research Log: SWE-agent Evaluation Post-Mortem & Optimization
Date: February 2, 2026
1. Progress & Root Cause Analysis (RCA)
- Storage & Environment Bottlenecks: * The evaluation endpoint’s 600GB storage reached capacity due to accumulated, uncleared Docker images, causing the task to crash at instance #298.
- Lessons Learned: While an additional 800GB was mounted, the default Docker root directory remained on the primary partition. Combined with Docker Hub rate-limiting and RunPod node instability, this led to multiple execution failures.
- Compute Resource Tuning: * Experimented with both NVIDIA RTX 4090 and A6000. Although the A6000 offers superior VRAM, improper parameter configuration resulted in sub-optimal performance. I have temporarily reverted to the 4090 to maintain a stable baseline.
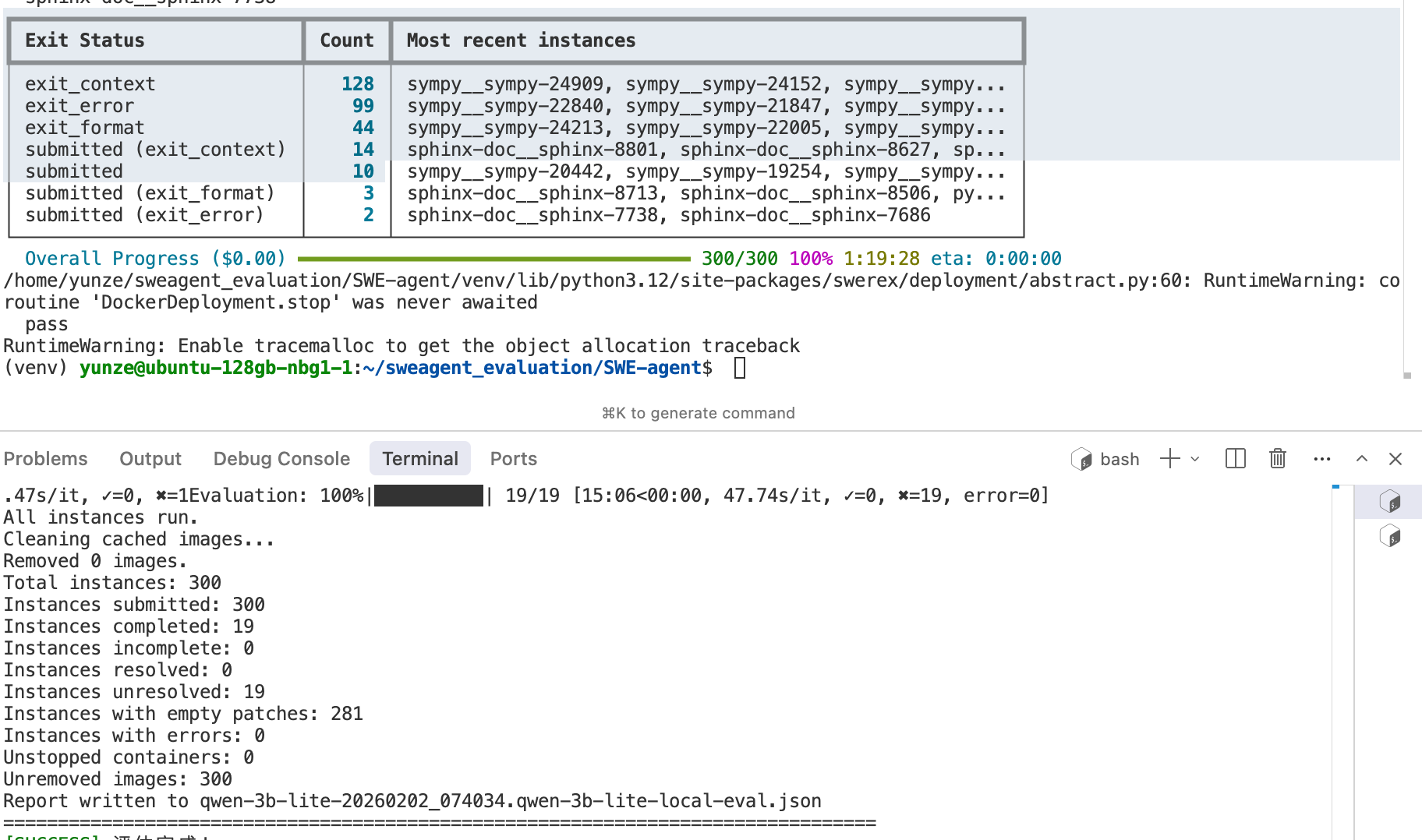
- Current Status: * After overnight debugging, I successfully completed a full inference pass.
- Throughput: 29 instances submitted during the SWE-agent inference phase (~9.7% submission rate).
2. Key Findings & Evaluation Metrics
- Evaluation Pipeline: Confirmed that SWE-agent does not trigger automatic evaluation by default (online evaluation requires explicit activation). I have now successfully established a local evaluation pipeline to bypass external dependencies.
- Preliminary Results: * Out of the 29 submissions, only 19 batches were non-empty.
- Pass@1 Rate: Currently 0%.
- Failure Analysis: Investigating two primary hypotheses:
- Pipeline/Environment Mismatch: The generated patches may not be applying correctly due to configuration errors or script mismatches.
- Model Capability Ceiling: The current model may lack the reasoning depth required for complex SWE-bench tasks.
3. Optimization Roadmap & Next Steps
- Throughput & Concurrency Tuning:
- Worker Optimization: Calibrate the number of parallel workers to find the “sweet spot” between VRAM utilization and system stability to prevent OOM (Out of Memory) crashes.
- Context Window Expansion: Test increasing the token limit from 8k to 16k to evaluate the marginal gain of longer context on problem-solving accuracy.
- Model Validation (Baseline Alignment):
- Following the advisor’s recommendation, I will benchmark Qwen2.5-Coder (Flash) with a 32k context window.
- Benchmark Goal: Target a 20-30% success rate. If achieved, it validates the pipeline; if it fails, it confirms an environmental issue.
- Config & Training:
- Refine the
swe-agent.yamlconfiguration to reduce inference redundancy. - Simultaneously push forward with SFT (Supervised Fine-Tuning) and Dataset Refinement.
- Refine the
4. Resource Utilization
- Cursor Pro Quota: Consumption is extremely high due to intensive code generation and debugging. The new account reached 1/3 of its weekly quota within the first 24 hours. Usage management is now a priority.