Daily Report: Experiment Design v3 Finalized · Dataset Ready — Feb 25, 2026
Experiment Design v3 Finalized
Today’s core work was finalizing the complete design for the second round of LoRA fine-tuning experiments. Building on the scoring system flaws exposed by the first round, v3 introduces several key changes:
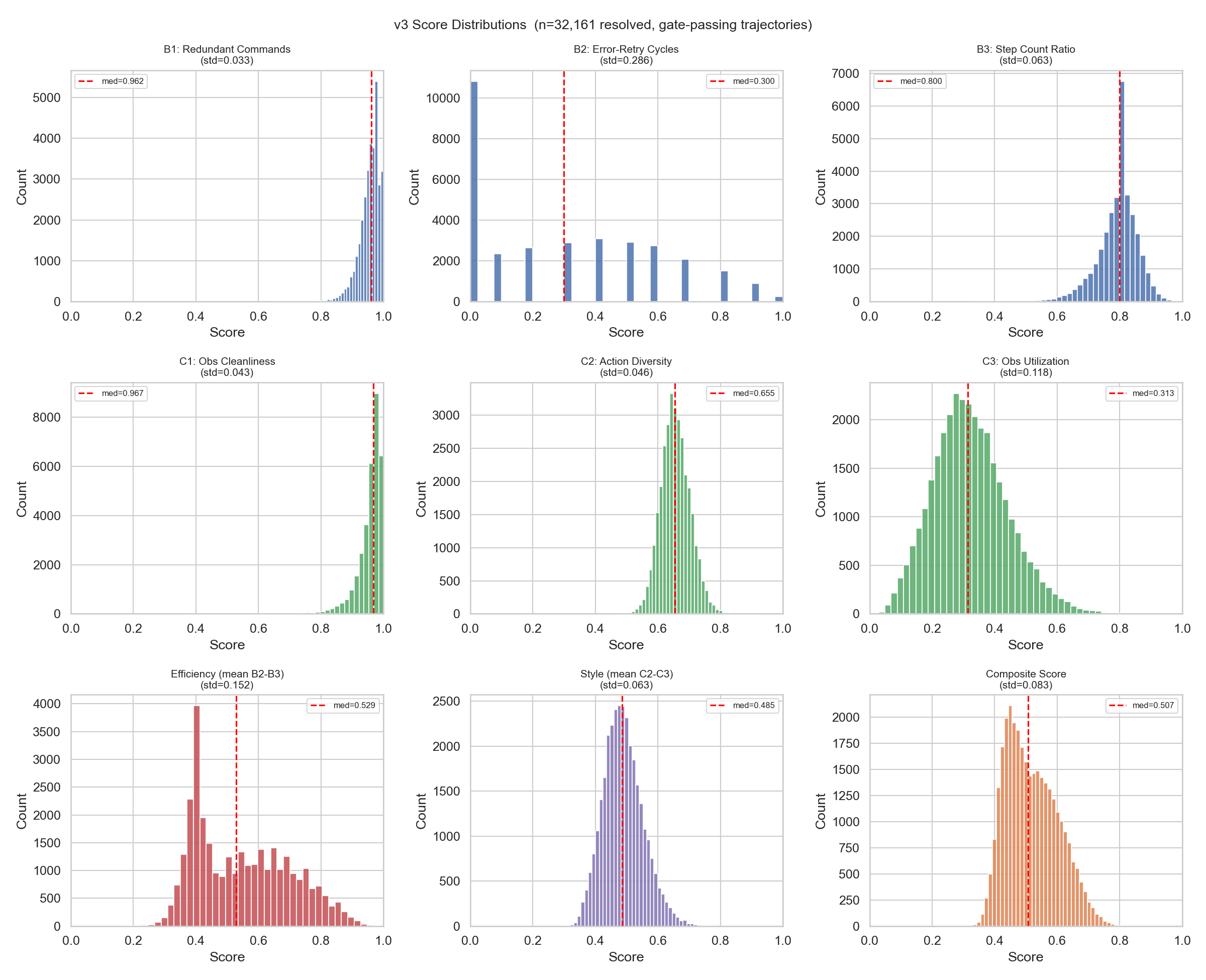
- Gate Conditions (Pre-filtering): Truncation Ratio (std≈0, no discriminative power) and Outcome Success (binary, unsuitable for mixing with continuous variables) were promoted from scoring dimensions to entry gates. Only complete, resolved trajectories enter the scoring pool.
- 4-Dimension Continuous Scoring: Within the resolved pool, trajectories are scored along Efficiency (Error-Retry Cycles + Step Count Ratio) and Style (Action Diversity + Observation Utilization) — two high-level dimensions with four sub-dimensions. Candidate sub-dimensions B1/C1 were excluded due to low variance (std < 0.05).
- Experimental Groups: 13 groups + 1 baseline, organized into Block 1 (data volume vs. strategy comparison), Block 2 (Efficiency vs. Style high-level ablation), and Block 3 (B2/B3/C2/C3 sub-dimension ablation). Three groups can reuse prior experiments; 11 groups require new training.
- Evaluation Protocol: Perplexity is computed on Gold / Random / Low-Q test sets to verify that the loss gradient aligns with the scoring ranking.
The chart below shows the distribution of each scoring dimension across 32,161 resolved trajectories. B1 (Redundant Commands) and C1 (Observation Cleanliness) are highly concentrated with almost no discriminative power, hence excluded. B2 (Error-Retry Cycles, std=0.286) stands out as the strongest discriminator and most effective scoring signal:
📄 Full experiment design document: Trajectory Quality-Aware Data Selection — Experiment Design v3
Dataset Ready
All training subsets have been preprocessed locally and uploaded to Hugging Face (davongluck/swe-bench-trajectory-quality-subsets) — 8,000 rows in total, covering all subsets needed for the 13 experimental groups.
Resume Exploration
The other task was exploring resume improvements. I’ve been using Overleaf + LaTeX templates, but felt the flexibility was limited — I wanted something that could be easily tailored for different positions. I tried AI-assisted resume generation, but the first attempt wasn’t quite production-ready in terms of layout and aesthetics. For now, LaTeX remains the more mature choice; it just takes time to find a good-looking template.
Tomorrow’s Plan
- Start LoRA fine-tuning on the second-round subsets (prioritizing Block 1 core comparison groups).
- Run perplexity evaluation after training completes, comparing performance across Gold / Random / Low-Q test sets.