Research Log: Research Progress & Workflow Evolution — Feb 6, 2026
1. Research Plan and Dataset Analysis
Today’s work continued to focus on refining the research direction and understanding the dataset, with solid and tangible progress.
- Yesterday, I redesigned the entire research plan with the help of Claude, restructuring the problem formulation, methodology, and validation strategy. At this point, the overall approach appears technically feasible and well-scoped.
- Today, I conducted a local analysis of the dataset, evaluating its strengths and weaknesses from multiple perspectives, including data distribution, quality characteristics, and potential limitations. This helped build a clearer understanding of the dataset’s suitability for the proposed study.
- All analysis code used in this phase was generated by Claude. In practice, Claude proved highly reliable in terms of code generation speed, logical completeness, and attention to implementation details, significantly reducing iteration overhead.
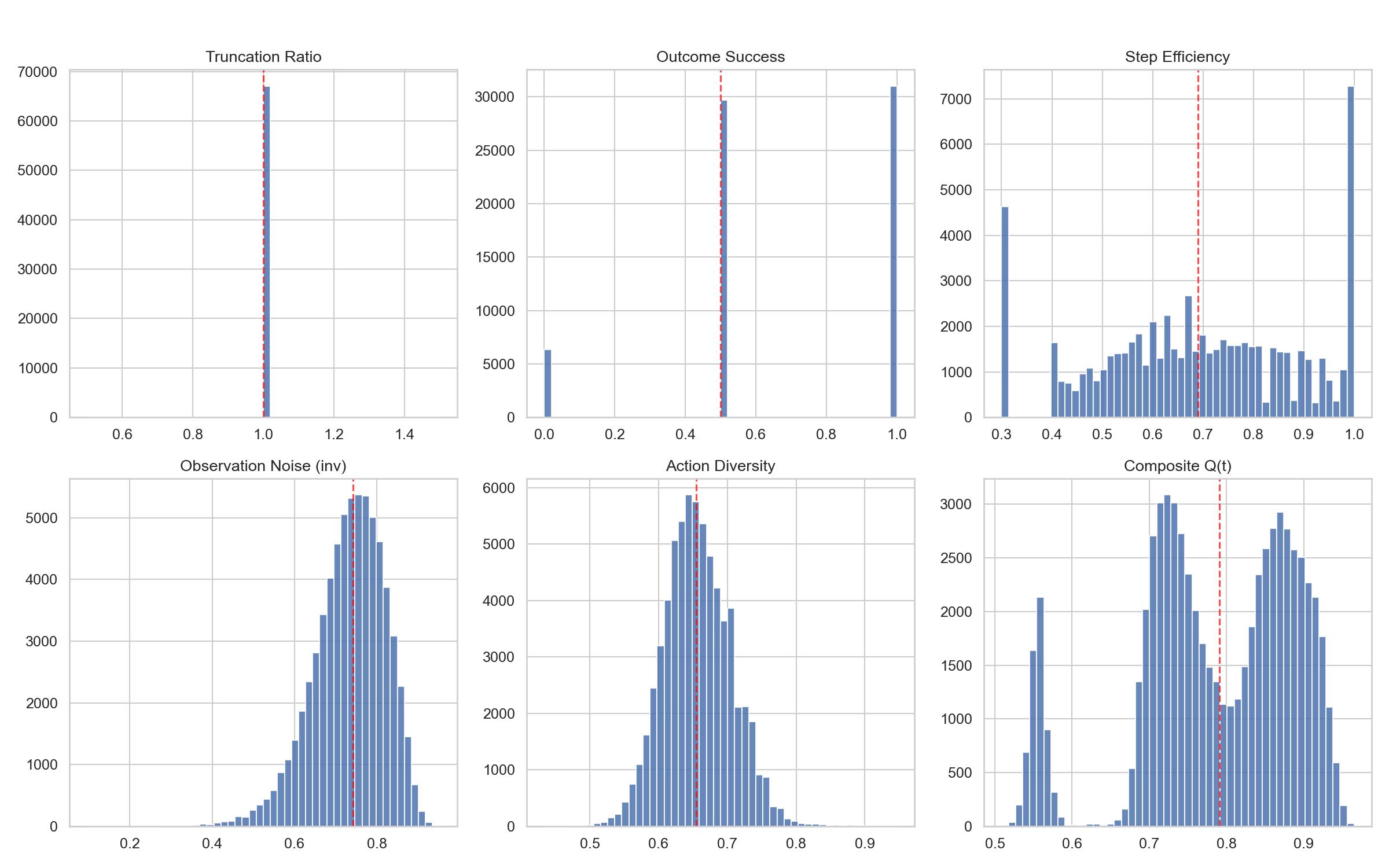
The figure below presents the results of today’s dataset quality analysis, covering six core dimensions: Truncation Ratio, Outcome Success, Step Efficiency, Observation Noise (inv), Action Diversity, and Composite Q(t). The red dashed lines indicate the mean or threshold values for each dimension, providing a clear view of the distribution characteristics and overall quality level of the dataset across different quality metrics.
2. Tooling Experience and Workflow Shift
As the project matures, my development workflow and tool preferences have also evolved.
- Compared to my previous experience primarily working with Cursor, the current workflow feels fundamentally different, shifting toward a more structured cycle of planning → generation → validation → iteration.
- I still use Claude models within Cursor for targeted fixes and refinements, and the overall effectiveness remains very strong.
- At this stage, it is clear that the earlier JupyterNotebook-style, fragmented coding approach is no longer suitable for the complexity of the current research and can be gradually phased out.
3. Next Steps and Technical Reflections
Based on today’s progress, the next technical milestones are becoming clearer.
-
If today’s remaining tasks proceed as expected, the next step will begin tomorrow: dataset splitting in preparation for model training.
-
Once the dataset has been properly split, I will move on to training-related work. The design and optimization of the training code will continue to rely heavily on Claude-assisted development.
-
Regarding issues observed in previously generated code, the main problems were concentrated in:
- the overall structure under Assistant-only loss settings, and
- the tokenizer selection and alignment strategy.
I now have several concrete ideas to address these issues and will revisit earlier implementations to perform a more systematic refactor and optimization.
Overall, this represents a meaningful and encouraging step forward. The direction is clearer, the tooling is stabilizing, and the groundwork for the training phase is largely in place. Onward tomorrow. 🚀