Research Log: Training Pipeline Stabilization & Evaluation Architecture — Feb 8, 2026
Training Pipeline Stabilization and Evaluation Architecture Setup
Today was a long but productive training day, mainly focused on debugging, stabilizing the training pipeline, and finalizing the evaluation-side architecture.
Overall progress can be summarized as:
morning bug fixing → afternoon infrastructure decisions → evening pipeline validation.
1. Training Progress Overview (Morning → Evening)
1.1 Morning: Fixing the set1 Training Failure
Yesterday, the training process for set1 consistently failed at step 11, preventing further progress.
This morning, after several adjustments to the configuration and runtime settings, the issue was successfully resolved, and the training pipeline was able to proceed normally.
1.2 Compute Strategy Adjustment: Moving Away from Spot Instances
Until the early afternoon, I was using RunPod Spot instances (preemptible GPUs).
While the hourly cost is lower, in practice:
- Spot instances are frequently interrupted
- Restoring the environment, checkpoints, and runtime configuration after interruption is extremely time-consuming
- The overall productivity loss outweighs the cost savings
As a result, I decided to switch to standard (non-preemptible) GPU instances.
Although the cost is approximately $0.5/hour higher, the improved stability significantly reduces wasted time and operational overhead.
1.3 Configuration and Code-Level Bug Fixes
During earlier iterations, some bugs were introduced due to issues in the configuration copying and synchronization mechanism.
- All identified issues have now been fixed
- The entire training mechanism is currently running end-to-end
- Remaining risks are primarily related to long-duration execution and checkpoint recovery, rather than logic errors
2. Training Progress and Checkpoint Recovery
2.1 Current Training Status
- From morning until around 2–3 PM, I continuously monitored the training remotely
- The first set completed successfully
- The second set is expected to take approximately 9 hours
2.2 Mid-Run Failure and Environment Upgrade
In the evening, I observed that:
- The first set completed normally
- The second set terminated unexpectedly at around sample 110
After investigation, it was determined that:
- Upgrading PyTorch to version 2.6 was required
The upgrade introduced temporary incompatibilities. However, after:
- Multiple iterations of testing
- Removing two conflicting plugins
I was able to successfully run the environment under PyTorch 2.6 and extract the checkpoint correctly.
2.3 Current Assessment
- The full pipeline is now fully operational
- Approximately 50 additional GPU hours are required to complete all remaining training
- Even if further interruptions occur, as long as checkpoints are preserved, training can be safely resumed
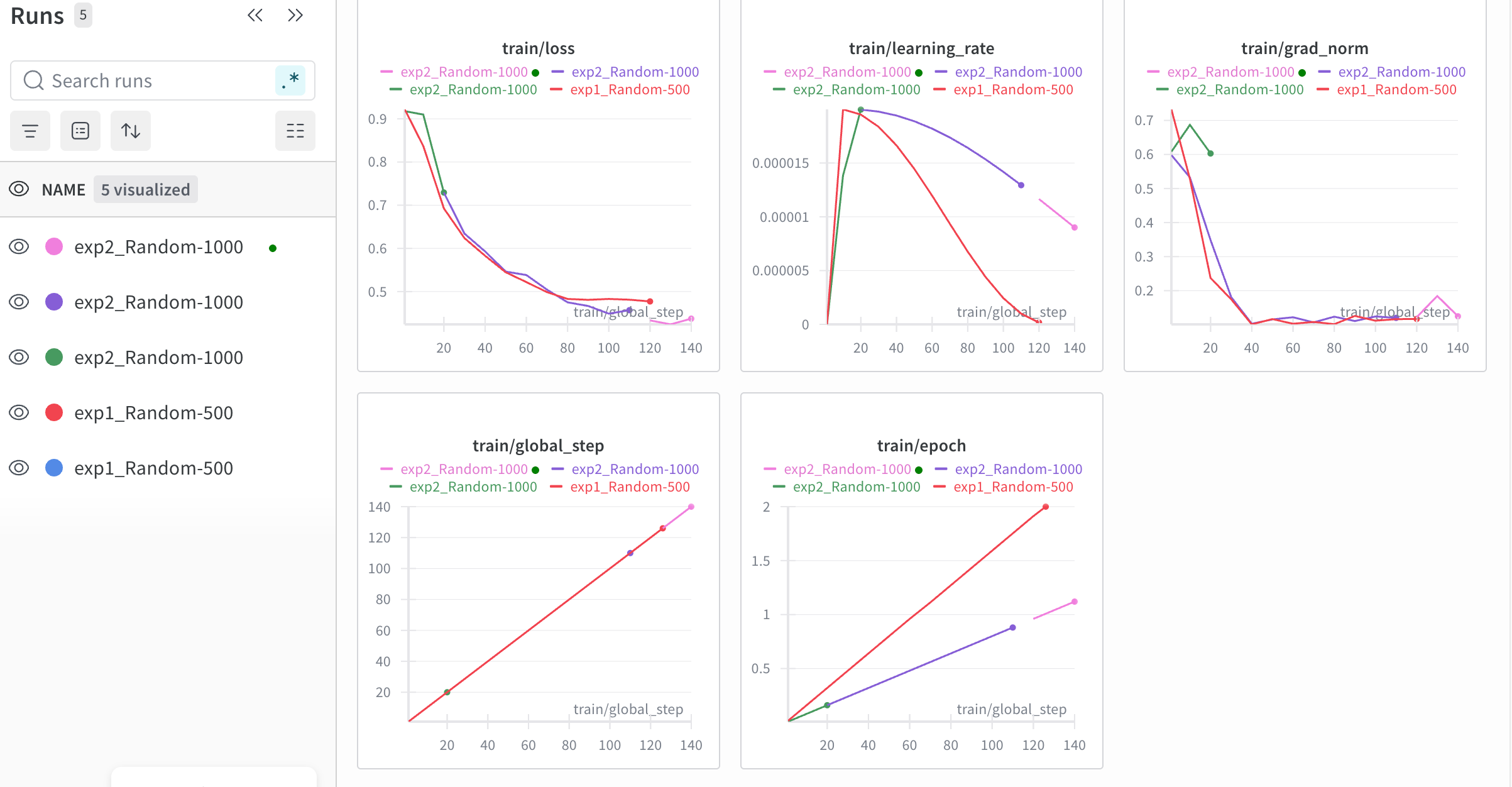
The screenshot below shows the current training dashboard: exp1 and exp2 have each been rerun several times due to mid-run failures or environment changes. The loss, learning rate, grad_norm, and other curves are now progressing normally across the runs; I’m hoping everything will finish successfully within about two days.
3. Evaluation Side and Architecture Design
3.1 Evaluation Pipeline Implementation
- The evaluation-side core code was completed today
- The evaluation scaffold is planned to follow the OpenHands architecture
3.2 Architectural Trade-offs
The initial design considered keeping both:
- the model-serving side, and
- the evaluation side
running continuously.
However, this approach was rejected due to:
- Excessive long-term GPU costs
- Poor cost-efficiency for idle resources
Final decision:
- Use on-demand execution
- Clearly separate inference and evaluation phases
3.3 Evaluation Run Strategy
- Running 3 seeds (3-run) would provide more statistically reliable results
- However, GPU consumption would be significantly higher
Current strategy:
- Start with 1-run evaluation
- If results are promising, perform a separate 3-run evaluation for robustness verification
4. Next Steps
- ✅ Local codebase is largely complete
- 🔜 Planned tasks for tomorrow:
- Run small-scale training tests on both the model side and server side
- Verify SSH connectivity
- Ensure the evaluation side can reliably control and trigger inference on the model side
- 🎯 Target outcome:
- A fully automated pipeline (inference + evaluation)
- Completion within ~10 hours for a full run
At this stage, speed is not the priority.
The primary goal is to make the entire pipeline robust and reliable. Once training results are available, the project can proceed to the next phase.
5. AI Agent Usage Summary
5.1 Claude
- Primary model in use: Claude Opus 4.6
- Very strong in research planning, code generation, and system-level reasoning
- Main drawback:
- Strict usage limits
- Global token caps become restrictive under heavy workloads
5.2 Codex
- Also tested Codex 5.3
- Current impression:
- Less reliable than Claude in complex reasoning tasks
- Possibly requires deeper usage patterns to unlock its strengths
- Advantage:
- More flexible usage limits
- Potentially suitable for future application or engineering-focused development
5.3 Other Tools
- Cursor Pro
- Used in a lightweight manner
- Helpful for resolving small issues via
automode under limited quotas
- ChatGPT 5.2
- Best suited for quick questions and sanity checks
- Used for lightweight, day-to-day problem solving
Summary
Although today involved long training hours and multiple interruptions, all critical components of the pipeline are now fully functional.
From system stability and checkpoint recovery to evaluation architecture design, the project has entered a controlled and scalable phase.
Overall assessment:
👉 Solid progress, correct direction, and a worthwhile day of work.