日报:vLLM 与 SWE Agent——2026年2月1日
2026年2月1日
前序
之前使用 H200 训练了 Qwen/Qwen2.5-Coder-3B 这个模型,并且在 RunPod 服务器上配置好了 vLLM 并行推理,用于 SWE Benchmark 的推理阶段。
评测阶段则是在 Hetzner 的 32 vCPU 服务器 上运行,使用推理阶段得到的预测文件进行评测。
但是我发现,大多数评测都会因为各种原因中途退出。
后来在和老师沟通后,才意识到需要使用标准的 SWE Agent 来进行评测,而不是当前这种方式。
今天所做的事情
- 在低级显卡上模拟模型搭载端的 RunPod 服务器流程,因为 vLLM 的依赖已经跑通,所以一次就成功了
- 在 SWE Agent 评测端(即 vCPU 服务器)上遇到了很多问题,不过最后终于可以完整跑通流程
- 第一次评测结果非常令人绝望,但在后续调整之后,终于解决了 RunPod HTTP 端口连接问题,可以继续跑后续流程了
- 模型方面也进行了更新。在大量报错之后,我发现 base 模型本身有问题,于是更换为
Qwen/Qwen2.5-Coder-3B-Instruct
并且目前只测试未经 SFT 的模型在 SWE Lite 上的通过率- 我的实验预期是:
- base 模型有一定通过率
- SFT 之后有一点点提升
- 在 refine 数据集之后再获得一些提升
- 我的实验预期是:
- 中间有一个插曲:我发现 SWE Agent 的评测方式是多轮与模型交互,
而我们训练使用的SWE-Gym / OpenHands-SFT-Trajectories是超长工具调用轨迹,token 数通常在 30k 以上
这让我开始怀疑:用 OpenHands 的训练数据去提升 SWE Agent 这种 benchmark,是否真的有效?
在和 AI 反复讨论之后,确认在思路层面是有一定可行性的 - 跑完后发现 submitted 率非常低,存在各种异常退出
- 跑 300 个评测大约需要 1 小时
- 但由于哄孩子睡觉,terminal 意外中断,没能看到最终结果
- 随后修改了 SWE Agent 的 YAML 配置文件,并将 Hetzner 服务器端的 worker 数优化到 6 个
- 最终仍然使用了旧版 YAML 文件
- 这部分显然还有优化空间,但流程已经可以持续跑起来了
- submitted 的概率有了一定提升
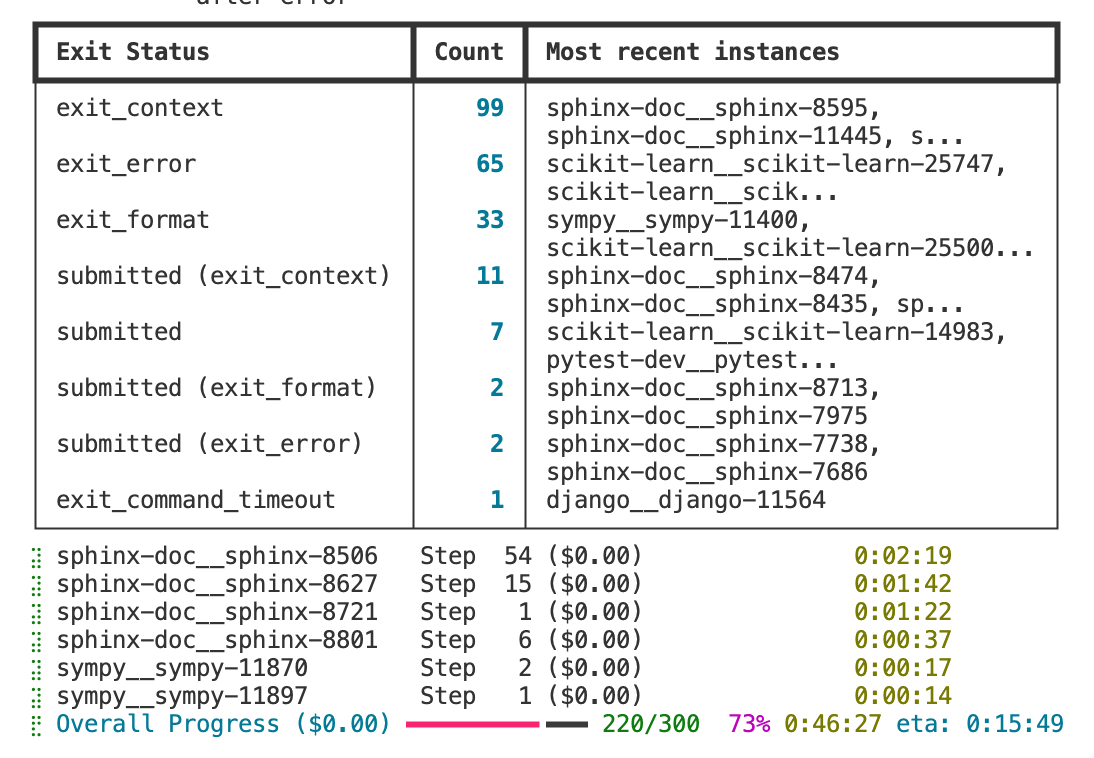 SWE Lite 评测中
SWE Lite 评测中