日报:SWE-agent 评测复盘——2026年2月2日
📝 日报:SWE-agent 评测复盘与优化方案
一、 实验进度与问题复盘
- 存储与环境瓶颈: 昨晚评测端 600G 存储空间溢出(因为我反复尝试docker的image并未清理),导致任务在第 298 条时中断。紧急扩容 800G 并挂载大盘重构服务器,但其实这样不解决问题,因为docker并不会挂载在扩容的硬盘上,后来又遭遇 Docker 拉取频率限制及 RunPod 节点波动,导致实验多次中断。
- 算力资源调优: 在 A6000 与 RTX 4090 之间进行了切换对比。初步反馈 A6000 虽显存大,但由于参数配置不当性能未达预期,目前切回 4090 保持稳定产出。
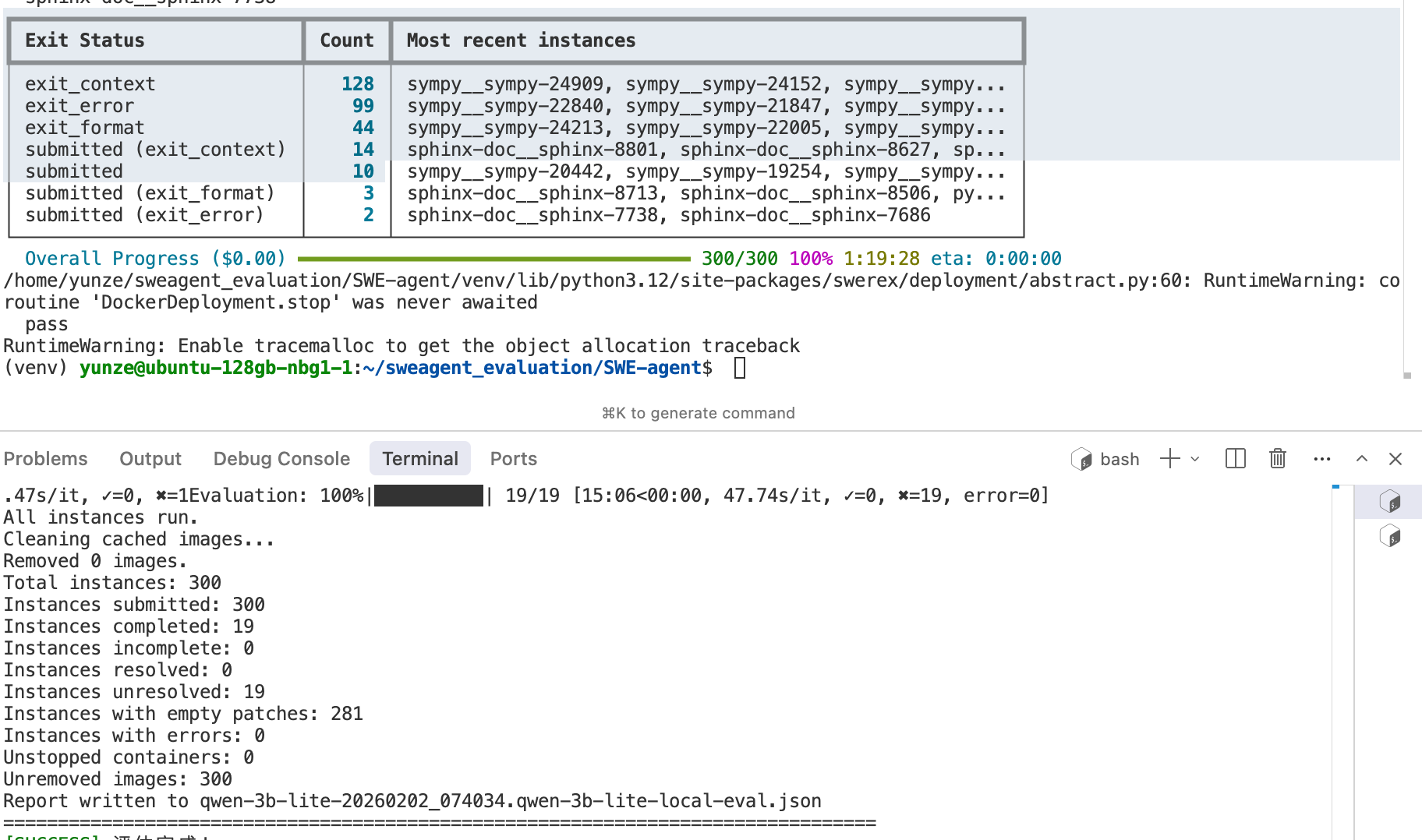
- 运行现状: 经过凌晨至早间的反复调试,现已完成一次完整推理。在 SWE-agent 推理阶段成功提交 29 个实例,提交率约为 9.7%。
二、 核心发现与评估结果
- 评估流程: 确认 SWE-agent 不具备自动 Evaluation 功能(需要开启,并且是在线评估)。通过对比 在线评估与本地评估,现已打通本地评测链路。
- 关键数据: 在提交的 29 个预测中,仅 19 个 Batch 非空,且初步测试通过率为 0。
- 归因分析: 目前存在两种可能性:
- 流程性错误: 环境配置或评估脚本导致 Patch 无法正确生效。
- 模型能力瓶颈: 当前模型逻辑推演能力不足以支撑 SWE-bench 的复杂任务。
三、 后续优化方向与待办事项
- 效率与并发优化:
- Worker 参数调优: 针对当前显存风险,计划通过实验寻找 Worker 数与显存占用的平衡点,防范爆显存导致的进程崩溃。
- 上下文长度测试: 考虑将 Token 从 8k 提升至 16k,观察长上下文对问题解决率的边际贡献。
- 模型验证方案:
- Baseline 对比: 采纳导师建议,引入 Qwen2.5-Coder (Flash) 配合 32k 上下文进行评测,若能达到 20%-30% 的成功率,则证明评测链路闭环,反之则需重新检查环境。
- 配置优化: 持续优化
swe-agent.yaml 配置文件,降低推理冗余。
- 数据与训练: 同步推进 SFT 训练 与 数据集 Refine 工作。
四、 资源损耗状态
- 由于高频的代码生成与调试,Cursor Pro 额度消耗极快(新账号首日消耗达 1/3),需注意后续额度规划。