日报:实验设计 v3 定稿 · 数据集就绪 — 2026年2月25日
实验设计 v3 定稿
今天的核心工作是敲定第二轮 LoRA 微调实验的完整设计方案。基于上一轮实验暴露的评分体系缺陷,v3 做了以下关键调整:
- 前置过滤(Gate Conditions):将 Truncation Ratio(std≈0,无区分力)和 Outcome Success(binary,不宜与连续变量混合)从评分维度改为入场门槛,仅允许完整且 resolved 的轨迹进入评分池。
- 四维连续评分:在 resolved 池内,按 Efficiency(Error-Retry Cycles + Step Count Ratio)和 Style(Action Diversity + Observation Utilization)两大维度、四个子维度评分。候选的 B1/C1 因方差过低(std < 0.05)被排除。
- 实验分组:共 13 组 + 1 baseline,分为 Block 1(数据量与策略对比)、Block 2(Efficiency vs Style 大维度消融)、Block 3(B2/B3/C2/C3 子维度消融),其中 3 组可复用旧实验,实际需新训练 11 组。
- 评测方案:在 Gold / Random / Low-Q 三个测试集上计算困惑度,验证 loss 梯度与评分排序的一致性。
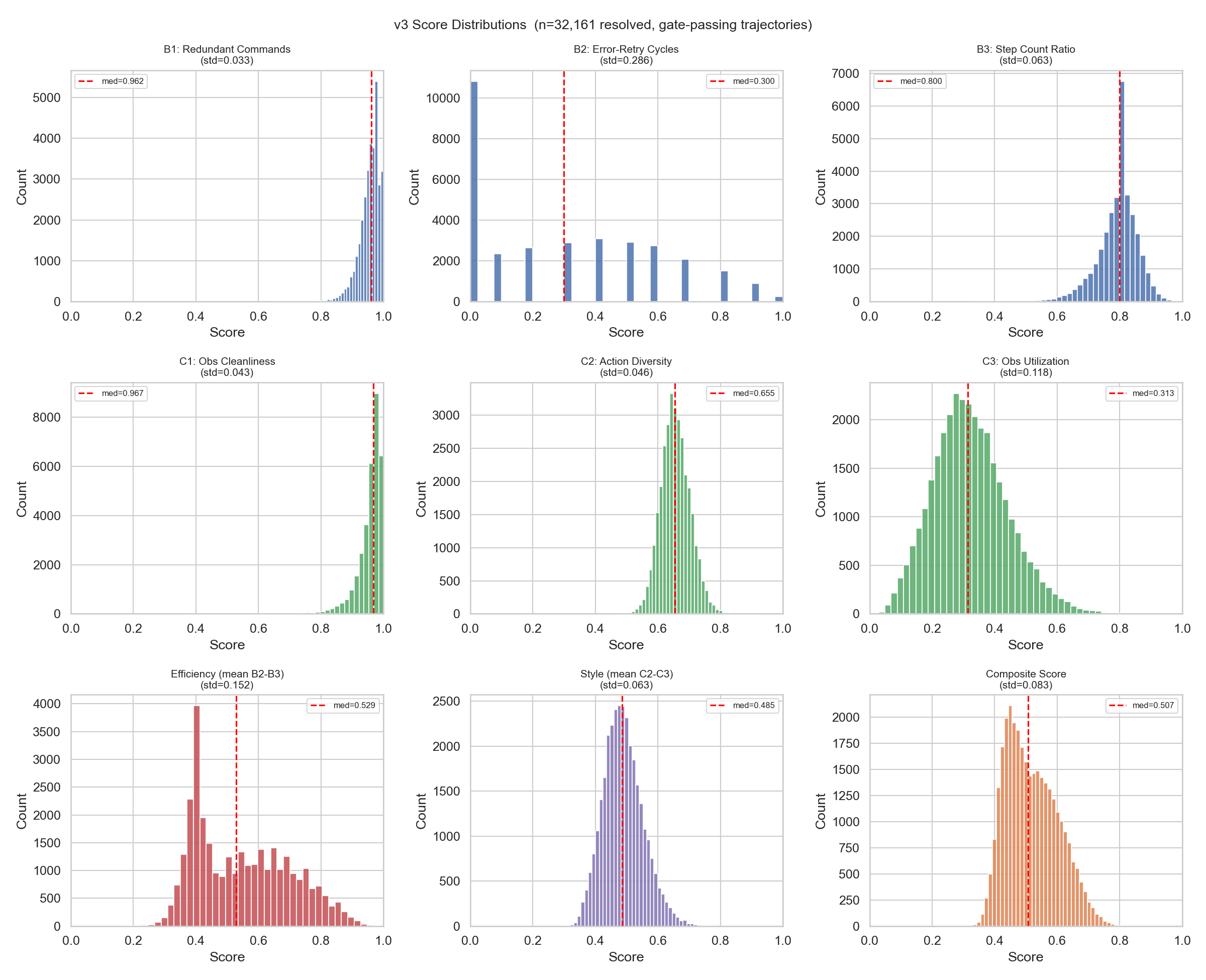
下图展示了 v3 评分体系在 32,161 条 resolved 轨迹上的各维度分布情况。可以看到 B1(Redundant Commands)和 C1(Observation Cleanliness)集中度极高、几乎无区分力,因此被排除;而 B2(Error-Retry Cycles, std=0.286)区分力最强,是最有效的评分信号:
📄 完整实验设计文档:轨迹质量感知数据选择 — 实验设计 v3
数据集就绪
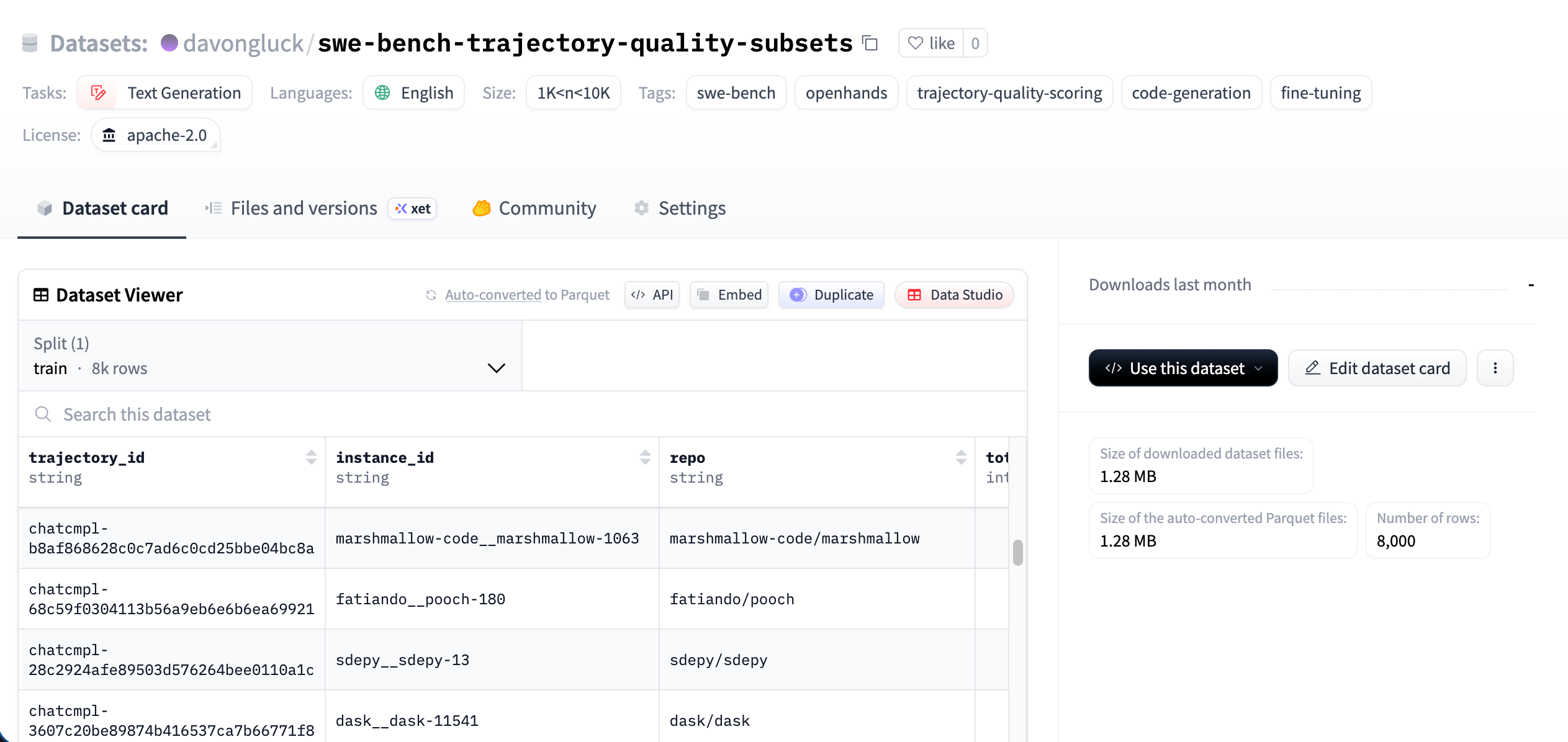
所有训练子集已在本地完成预处理,并上传至 Hugging Face(davongluck/swe-bench-trajectory-quality-subsets),共 8,000 条数据,涵盖 13 组实验所需的全部子集。
简历探索
另一件事是尝试改造简历。之前一直用 Overleaf + LaTeX 模板,感觉自由度不够,想找一种能针对不同岗位灵活调整的方案。试了一下 AI 辅助生成,但初次尝试效果不太理想 — 排版和审美上还达不到直接可用的水平。目前看来 LaTeX 仍然是更成熟的选择,只是需要花时间挑一个好看的模板。
明日计划
- 启动第二轮子集的 LoRA 微调训练(优先 Block 1 的核心对比组)。
- 训练完成后进行困惑度评测,对比各组在 Gold / Random / Low-Q 测试集上的表现。