日报:研究进展与工作流演进 — 2026年2月6日
一、研究计划与数据集分析
今天的工作重点依然围绕研究方案与数据集本身展开,但整体推进非常顺利。
- 昨天我基于 Claude 重新梳理并设计了完整的研究计划,从研究目标、方法路径到验证方式都进行了系统性重构。目前来看,该方案在理论和工程实现层面都是可行且清晰的。
- 今天主要通过本地分析的方式,对当前使用的数据集进行了深入评估,从数据分布、质量差异到潜在问题都做了较为全面的分析,对其优势与局限有了更明确的认识。
- 本阶段所使用的分析代码全部由 Claude 生成。在实际使用中,Claude 在代码生成速度、逻辑完整性以及对细节的考虑上都表现得非常可靠,大幅降低了试错成本。
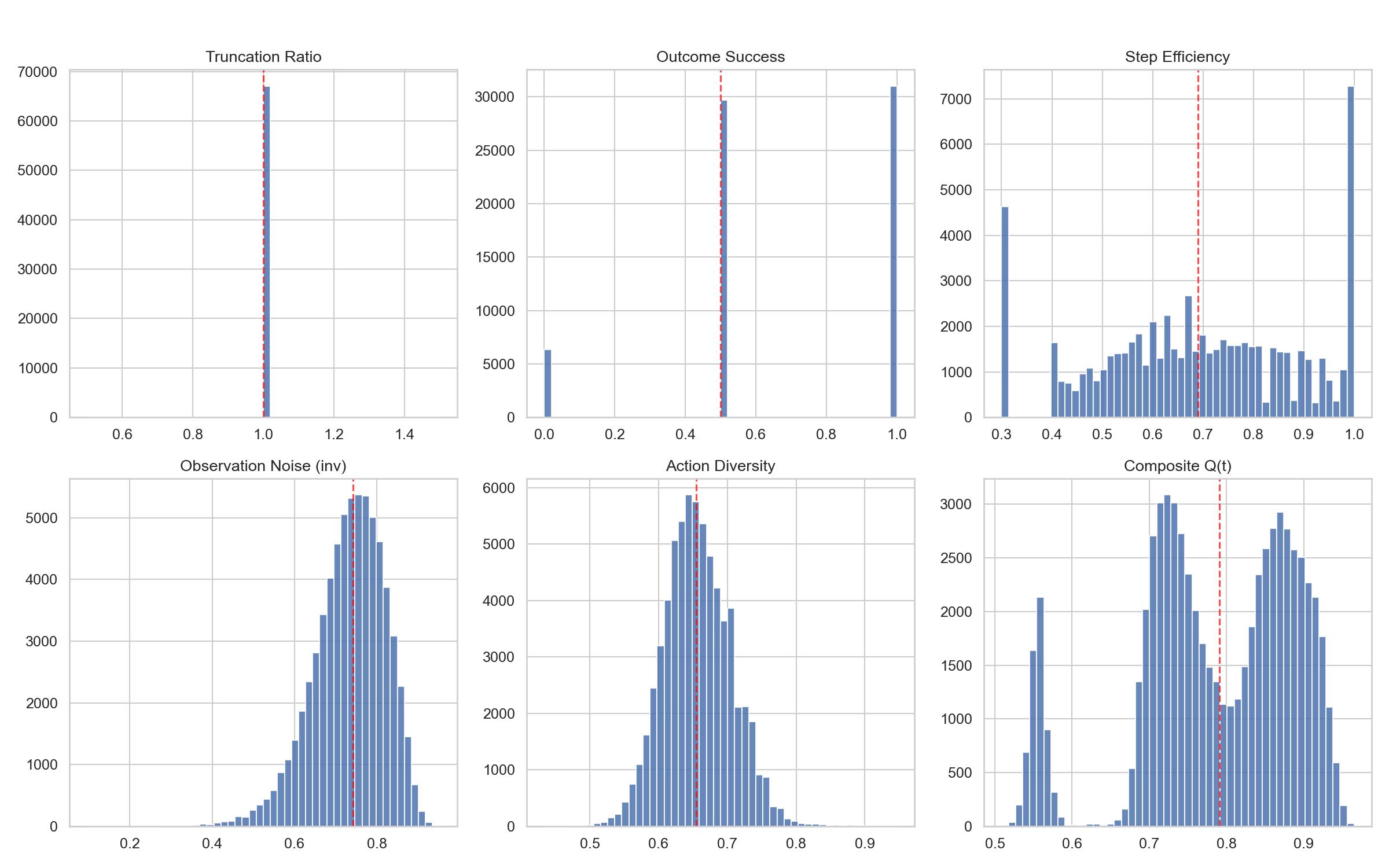
下图展示了今天对数据集进行质量分析的结果,涵盖了六个核心维度:截断比率(Truncation Ratio)、结果成功率(Outcome Success)、步骤效率(Step Efficiency)、观测噪声(Observation Noise)、动作多样性(Action Diversity) 以及 综合质量评分(Composite Q(t))。红色虚线标记了各维度的均值或阈值位置,可以直观地看出数据集在不同质量指标上的分布特征和整体质量水平。
二、工具体验与开发方式的变化
随着流程逐渐稳定,我对开发工具和使用方式也有了明显的认知变化。
- 相比此前主要使用 Cursor 的开发体验,现在的整体工作流已经发生了本质上的改变,更偏向于「规划 → 生成 → 验证 → 迭代」的节奏。
- 在 Cursor 中我仍然会使用部分 Claude 模型进行局部修补和调整,但在当前任务场景下,整体效果依然非常理想。
- 可以明确的是,之前那种偏 JupyterNotebook 式、碎片化的代码书写模式已经不再适合当前阶段的研究复杂度,可以逐步放弃。
三、后续计划与技术思考
在当前进度基础上,接下来的技术路线也逐渐清晰。
-
如果今天整体推进顺利,明天将进入第二阶段:对数据集进行正式的切分,为后续训练做准备。
-
数据集切分完成后,即可开始着手模型训练相关工作,其中训练代码的设计与优化仍将高度依赖 Claude 的辅助能力。
-
对于此前生成代码中暴露出的一些问题,目前已有较为明确的认识:
- 错误主要集中在 Assistant Only(仅计算 Assistant Loss)模式下的整体结构设计;
- 以及 Tokenizer 选择与对齐策略不合理所带来的潜在影响。
针对上述问题,我已经形成了一些初步思路,后续将结合此前的代码实现,对整体结构进行系统性的优化。
整体来看,这是一次非常扎实且关键的进展。方向清晰、节奏稳定,明天继续推进。💪