日报:训练流程稳定化与评测架构搭建 — 2026年2月8日
训练流程推进与评测架构搭建
今天是一个训练时间很长、但关键问题逐步被解决的一天。整体节奏可以概括为:
上午修 Bug → 下午调整算力策略 → 晚上打通关键流程。
一、训练过程回顾(Morning → Evening)
1. 早晨:set1 训练 Bug 修复
昨天在 set1 的第 11 步训练过程中持续报错,导致流程无法继续。
今天上午通过对配置和运行参数进行多轮调整,最终成功修复了该问题,训练得以继续推进。
2. 算力策略调整:放弃 Spot 实例
在今天下午之前,我一直使用的是 RunPod 的 Spot 实例(可被打断):
- 虽然单价更低,但
- 一旦被打断,后续的恢复、环境重建和配置衔接成本极高
- 实际上对整体进度和精力消耗非常不友好
综合时间成本后,我决定改用 普通(不可打断)GPU 实例,
虽然价格贵了大约 $0.5 / 小时,但稳定性和效率明显更高,从长期看反而更省时间。
3. 配置与代码层面的 Bug 修复
在此前修改 config 的过程中,
由于 代码复制 / 配置同步机制存在问题,引入了一些隐性 Bug。
- 这些问题在今天已全部定位并修复
- 当前训练机制整体已经跑通
- 后续主要是长时间运行与断点恢复问题,而非逻辑性错误
二、训练进度与断点处理
1. 当前训练状态
- 从早晨到下午两三点,我一直在 远程监控训练进度
- 第一个 set 已顺利跑完
- 第二个 set 预计需要约 9 小时
2. 中途断点与环境升级
- 晚上发现:
- 第一个 set 正常完成
- 第二个 set 在 约第 110 条数据处中断
- 排查后确认:
- 需要将 PyTorch 升级至 2.6
升级过程中出现了一定的不兼容问题,但通过:
- 多次尝试
- 卸载了 两个存在冲突的插件
最终成功在 PyTorch 2.6 环境 下:
- 正确加载环境
- 成功提取 checkpoint
3. 当前判断
- 目前整个流程已经完全跑通
- 预计还需要 约 50 小时 GPU 时间 即可完成全部训练
- 即使后续再出现中断,只要 checkpoint 正常,均可无损续跑
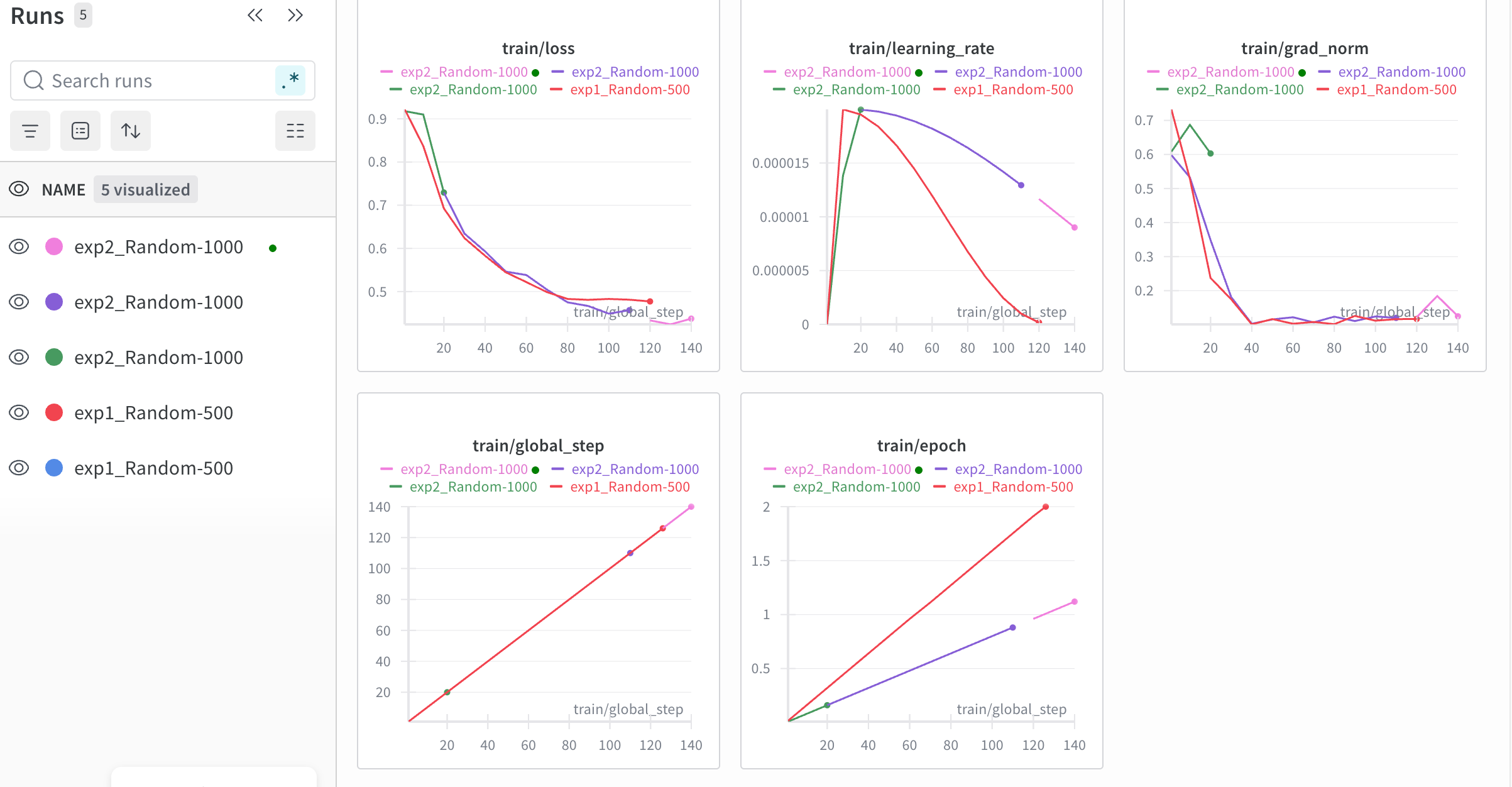
下图是当前的训练监控截图:exp1 和 exp2 都因中途断点或环境调整重跑了几次,目前多条 run 的 loss、learning rate、grad_norm 等曲线已能正常推进;希望约两天内可以全部顺利跑完。
三、评测端设计与整体架构规划
1. 评测端实现
- 今天完成了 评测端核心代码的生成
- 计划采用 OpenHands 架构 作为评测 scaffold
2. 架构取舍
最初的方案是:
- Model 端 + 评测端 长期常开
但经过评估发现:
- GPU 服务器长期占用成本过高
- 性价比不合理
最终决定:
- 按需启动
- 推理与评测阶段分离执行
3. 评测轮次策略
- 理论上 3-run(多随机种子)结果更可靠
- 但 GPU 消耗非常大
当前策略:
- 先跑 1-run
- 如果效果显著,再单独补充 3-run 做稳定性验证
四、后续计划
- ✅ 本地代码已基本完成
- 🔜 明天计划:
- 在 模型端 & 服务器端 分别进行小规模训练测试
- 检查 SSH 连通性
- 确保评测端可以稳定控制模型端执行推理
- 🎯 理想目标:
- 整个自动化流程(推理 + 评测)
- 在 10 小时内完成一次完整闭环
当前并不追求速度,核心目标是彻底把流程跑稳、跑通。
等训练结果产出后,再进入下一阶段的分析与实验设计。
五、AI Agent 使用情况总结
1. Claude
- 当前主要使用 Claude Opus 4.6
- 在研究规划、代码生成和系统性思考方面非常强
- 但:
- 各类额度限制
- Token 总量上限
确实在高强度使用场景下比较令人头疼
2. Codex
- 同时测试了 Codex 5.3
- 整体感觉:
- 稳定性和可靠性暂时不如 Claude
- 可能还没有完全摸清其最佳使用方式
- 优点是:
- 额度相对友好
- 如果后续进行 App 或工程类开发,可能会继续尝试
3. 其他工具
- Cursor Pro
- 主要用于轻量辅助
- 在额度有限的情况下,配合
auto解决一些小问题
- ChatGPT 5.2
- 更适合日常快速提问
- 用于确认细节或做即时判断
总结
虽然今天训练时间漫长、问题频发,但关键流程已经完全打通。
从系统稳定性、训练可续性到评测架构,整体已经进入一个可控、可扩展的阶段。
总体评价:
👉 进展扎实,方向正确,是值得的一天。